Overview Video
Quick Summary
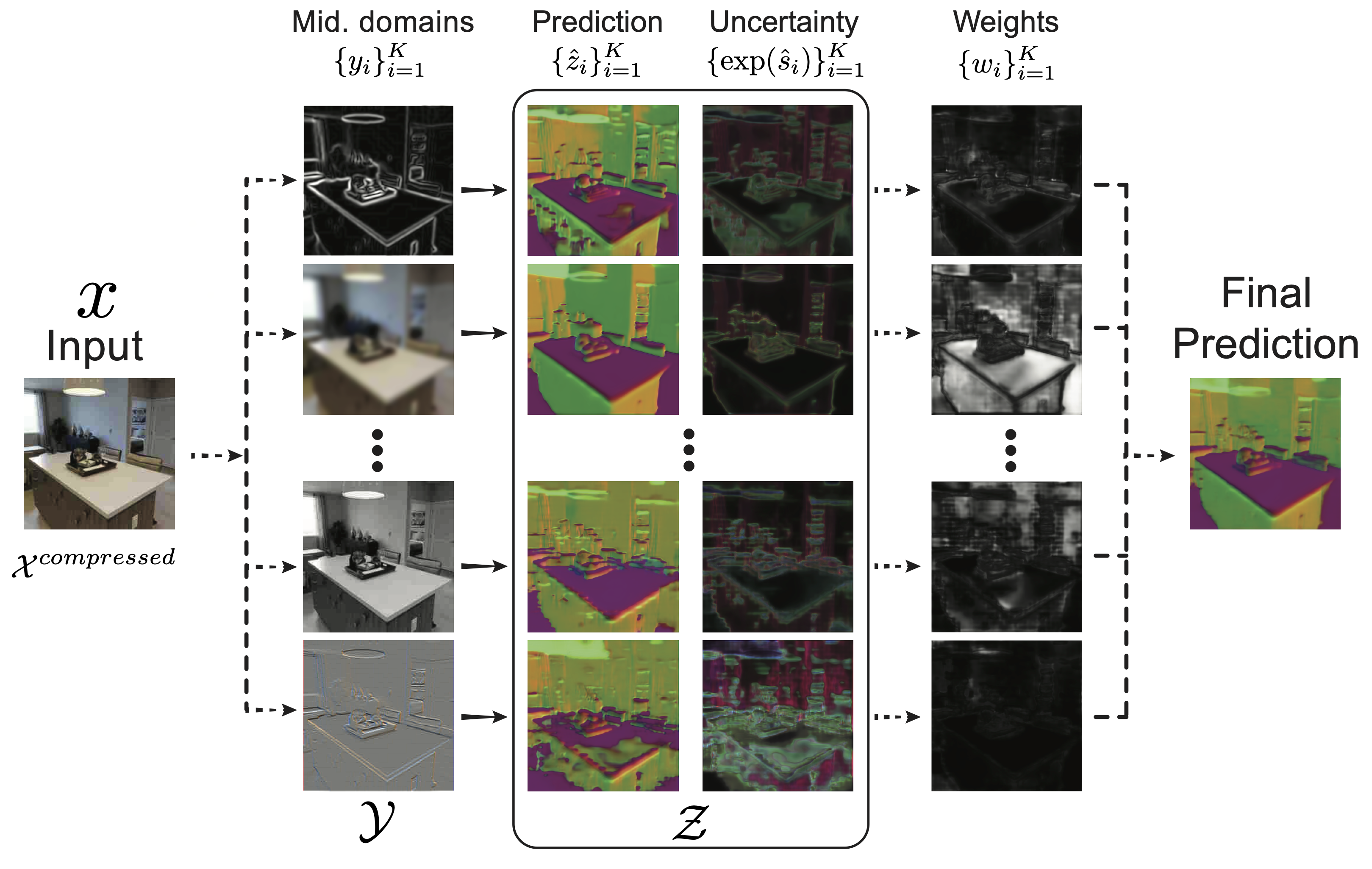
An overview of our method for creating an ensemble of diverse prediction paths. A network is trained to go from an input that has undergone an unknown distribution shift (e.g. JPEG compression degradation) to a target domain, e.g. surface normals, via several middle domains, e.g. 2D texture edges, low-pass filtering, greyscale, emboss filtering, etc. We then compute the corresponding weights of these predictions based on their uncertainties. The final prediction is obtained by a weighted average. Solid arrows represent learned mappings and dashed ones represent analytical mappings.
Robustness Of Neural Networks
The video below shows the predictions of standard methods against our proposed approach applied frame by frame on a query YouTube video. Our predictions are notably more resistant to natural distortions that occur across video frames.
(Note: Videos on page best seen in HD)
How Do We Obtain Robust Predictions?
We first select a set of middle domains from which we learn to predict the final domain. Each path reacts differently to a particular distribution shift, so its prediction may or may not degrade. We also estimate the uncertainty of the each path's prediction, which allows us to employ a principled way of combining them. Prior knowledge of the relationship between middle domains is not needed as their contribution to the final prediction are guided by their predicted uncertainties. The middle domains we adopt are all self-supervised (they can be programmatically extracted), thus, this framework does not require any additional supervision/labeling than what the dataset comes with. We show that the method performs well, insensitive to the choice of middle domains and it generalizes to completely novel non-adversarial and adversarial corruptions.
The Method In Action
The quality of the final prediction depends on the following elements:
- • For each pixel, at least one middle domain is robust against the encountered distortion,
- • The uncertainty estimates are well correlated with error, allowing the merger to select regions from the best performing path. Uniform merging does not take into account the uncertainties and consequently lead to worse predictions.

How does it work? Each network in each path receives different cues for making a prediction, due to going through different middle domains. Left: Given a distorted pixelated query, each path (columns) is affected differently by the distortion, which is reflected in its prediction, uncertainty, and weights (lighter means higher weights/uncertainty). The inverse variance merging uses the weights to assemble the final prediction that is better than each of the individual predictions. Right: Similarly, for a query with glass blur distortion, the method successfully disregards the degraded predictions and assembles an accurate final prediction. Note that the proposed method (inverse variance merging) obtains significantly better results than learning from the RGB directly (leftmost column of each example) which is the most common approach. The elliptical markers denotes sample regions where the merged result is better than all individual predictions.
Addressing Overconfident Inaccurate Predictions
We propose a calibration step, denoted as sigma training to encourage the network to output high uncertainties while keeping predictions fixed. The video at the right shows the predictions and uncertainties before and after this step on an image corrupted with increasing distortion. Before sigma training, when the model produces poor results, its uncertainty does not increase correpondingly. After sigma training, the uncertainty estimates have a stronger correlation with error.
Sample Results
Some qualitative results on videos and image queries are shown below. The former are on external YouTube videos and the predictions are made frame-by-frame with no temporal smoothing. Zoom in to see the fine-grained details. See the paper for full details.
Key takeaways:
- • Using middle domains I. promotes ensemble diversity, which improves performances by decorrelating errors, II. reduces the tendency of individual networks to learn from superficial cues. The uncertainty based merging allows the method to select regions from the best performing path. This allows us to attain:
• Robustness against natural distortions: We compare against several baselines and show that our method is robust to a wide range of natural distortions. In particular, we compare against adversarial training which is a popular way of making networks robust and show that it does not lead to robustness against natural distortions.
• Robustness against adversarial attacks: The method is also shown to be more robust to attacks compared to baselines without adversarial training.
• Robustness on classification tasks: The improved performance on ImageNet and CIFAR confirms the basic value of using middle domains.
- • Furthermore, improvements in robustness does not sacrifice performance on in-distribution data and has a negligible increase in computational cost compared to standard ensembles.
Results on pixel-wise prediction tasks
The predictions below for the different target domains further demonstrates the generalizability of our method.

Qualitative results under synthetic and natural distribution shifts for normal, reshading, and depth. The first four rows show the predictions from a query image from the Taskonomy test set under no distortion and increasing speckle noise. Our method degrades less than the other baselines, demonstrating the effectiveness of using different cues to obtain a robust prediction. The last three rows shows the results from external queries. Our method demonstrates better generalization to images considerably different from the training dataset.
Improvements are further supported by quantitative results. The l1 error over a wide range of distortions are lower for the proposed approach (inv. var. merging) compared to the baselines in all three target domains and shift intensities.
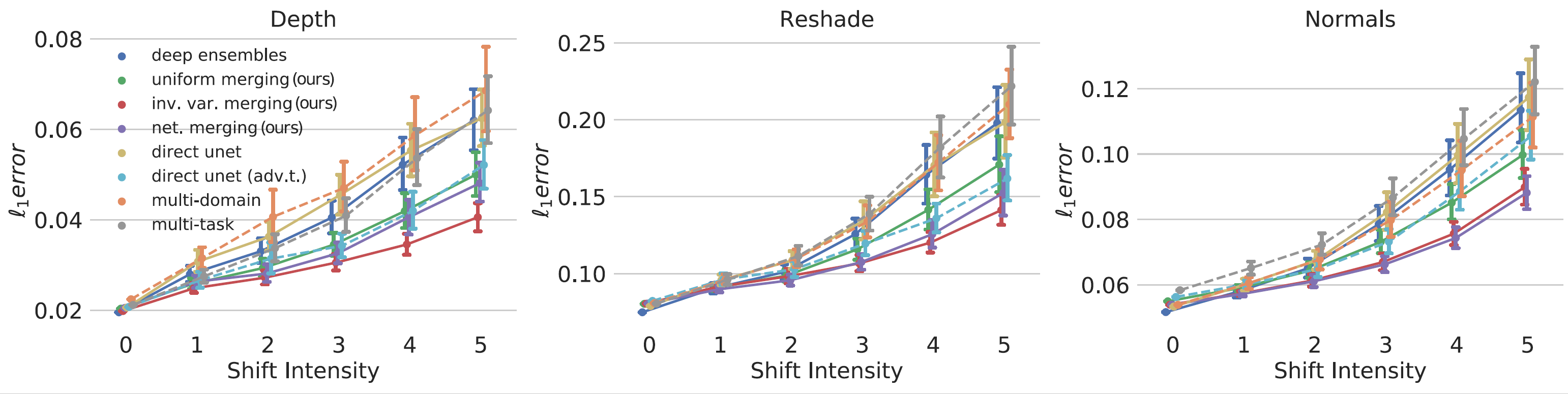
Quantitative results: Average l1 loss over 11 unseen distortions from Common Corruptions. Error bars correspond to the bootstrapped standard error. Our proposed approach is more robust against distribution shifts.
Generalization of sigmas to distribution shifts:
We have showed that our method returns predictions that are robust under a wide range of distribution shifts. Are our predicted uncertainties also able to generalize under distribution shifts, i.e. do we get high uncertainties when predictions get worse?
To investigate this, we consider epistemic uncertainty which is used to capture the model's uncertainty and is an indicator of distribution shifts.
The video at the right shows the predictions and epistemic uncertainties on an image corrupted with increasing distortion. Deep ensembles produce overconfident uncertainties under distortion, while our method shows an increasing trend.
Results on adversarial attacks
Results on classification task
The proposed method is not limited to regression tasks. The video below shows the performance on ImageNet under increasing distortion and clean inputs. Our method performs noticeably better compared to baselines by only averaging predictions from a diverse set of middle domains. See the paper for more details and additional results.
Paper

Robustness via Cross-Domain Ensembles.
Yeo*, Kar*, Sax, Zamir.
ICCV 2021 [Oral]
Arxiv 2021
Team

Teresa Yeo
EPFL
Oğuzhan Fatih Kar
EPFL
Alexander (Sasha) Sax
UC Berkeley